让不懂建站的用户快速建站,让会建站的提高建站效率!

据多家巨擘照料机构最新研判,2026 年 中枢存储供应链的结构性阑珊已成行业刚性实践,供需缺口执续扩大且很可能无间至 2027 年。不仅是存储部件的单点问题,刻下,生成式 AI 正从期间尝鲜全面走向规模化落地,大模子期间的专揽场景正在从教师为主转向训推并重和轻量推理,PD 分离、KV Cache 等期间的规模化专揽在执续提高推理后果的同期,对高带宽、大容量的 GPU 内存提议了极致严苛的条目,显存资源垂危带来的行业惊悸正在执续蔓延。叠加存储部件供应阑珊与价钱跳升的双重压力,AI 产业发展濒临严峻的资源与老本挑战,单纯依靠 “力大砖飞” 的硬件堆叠,不仅会大幅推高每 token 老本,更受供应链产能制约难认为继,严重影响产业良性发展。
因此,通过软硬件协同优化提高 GPU 等要道部件的使用后果,成为破解内存供应链阑珊惊悸、假造总体领有老本的中枢旅途。
破局逆境·架构解密:新华三打造智算推理新引擎
刻下,大模子推理濒临的发展逆境已不行躲闪:模子对算力与显存的需求呈指数级增长,关系词堆叠GPU硬件所带来的老本与能效压力,严重制约期间的可执续发展。尤其在处理长文本、多轮对话等场景时,模子为保存高下文而生成的KV Cache(键值缓存)会急剧扩张,不仅多半占用贵重的GPU显存,更导致多半访佛料想,成为制约反馈速率、推高运营老本的瓶颈。
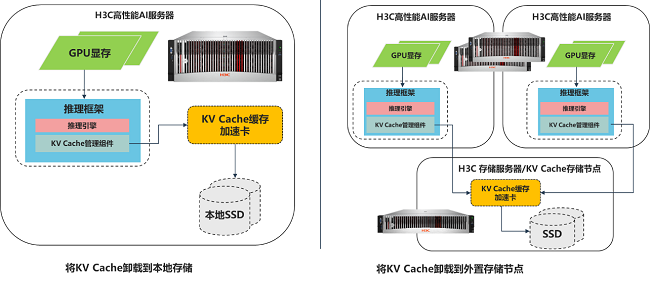
直面老本与后果的核肉痛点,紫光股份旗下新华三集团打造出效力兼备的大模子推理场景加快决议。通过其自研的定制化ASIC芯片提供硬件级加快,将KV Cache从GPU内存卸载到指定存储节点,构建专为AI联想的“下一代内存层”,玩忽GPU显存的压力,从而在系统层面竣事了存算资源的新均衡。新华三凭借自己强大的硬件集成与全栈优化技艺,驱动业内前沿科技与自研AI职业器的翻新耦合,经过深度的测试调优最终变成了大模子推理加快的最好履行,为业界提供了一条性能与老本兼顾的全新推理范式。
从部署情势来看,本决议既复旧单机情势部署,成功提高单台AI职业器的推感性能。也复旧通过外置存储节点的式样同期对接多台AI职业器,提高集群的推感性能。
实教师证·性能跃升:中枢策画翻倍,推升深度推理新速率
为深远探讨本决议中KV Cache卸载对推感性能的提高,新华三基于自研高性能AI职业器进行基准测试,要点神情在吞并机型上,动手DeepSeek-V3-671B模子时,领受圭表推理职业和领受KV Cache卸载加快决议的两种模式下的性能各别,阔别构建10K和30K的文本输入,模拟骨子专揽场景中的多轮对话推理进程,以确保测试终局具有骨子参考价值。经多轮考证,领受KV Cache卸载加快决议的推理中枢策画显赫优化:
• 并发用户数提高200%:在相易TPOT(每个Token生成的平均蔓延,ms)遗弃下,一样的算力资源可复旧的并发数显赫提高,保险用户体验的同期复旧职业更多的用户。
• 推理蔓延大幅假造:TTFT(首Token生成的蔓延,ms)假造70%,TPOT(每个Token生成的平均蔓延,ms)假造30%,大幅缩小反馈蔓延,提高用户体验。

场景适配·全域掩饰:贴合企业GenAI落地需求
• 交互式专揽(多轮对话): 如聊天机器东说念主、智能客服等。这类专揽中,用户与模子的交互是多轮的,后续轮次的输入时时依赖于前序对话的高下文。通过快速加载存储历史 KV Cache,未必大幅缩小反馈蔓延,提高用户体验。
• 长高下文处理: 关于需要处理数千以至数万Tokens高下文的任务(如长文档问答、代码生成、复杂请示清醒),GPU内存容量往往成为瓶颈。本决议提供的PB级KV Cache扩展技艺,使得处理这类长高下文任务更为冷静,幸免了因GPU内存不及导致的性能着落或任务失败。
• 高并发推理职业: 在面向多半用户的在线推理职业中,系统需要同期处理多个并发苦求。本决议通过高效的KV Cache责罚,未必复旧更多并发会话,显赫提高系统的全体蒙胧量(RPS),从而在相易的GPU资源下职业更多用户。
跟着模子规模的扩大和用户基数的扩张,大模子推理后果正成为AI基础才略性能的要道策画。新华三凭借多年来在AI规模的期间翻新与履行探索推出推理加快决议,并进行悉心的调优履行,充分考证了该决议在提高推理后果方面的显赫上风,进一步加快GenAI专揽的发展。
GenAI期间,推理加快注定是一条执续提高、永无特别的翻新之路。面向改日,新华三将执续在AI Infra规模深耕,提供更多针对不同场景,联想基于不同加快层级、不同加快介质等期间阶梯的推理加快决议,匡助企业和拓荒者更闲适地顶住大模子落地专揽的复杂性和规模挑战,鼓吹AI期间在更多规模的专揽和翻新。
实盘配资在股票交易记录中如何体现提示:本文来自互联网,不代表本网站观点。